This article is more than 1 year old
OpenAI, DeepMind double team to make future AI machines safer
New algorithm keeps humans firmly in the loop during training
Researchers from OpenAI and DeepMind are hoping to make artificial intelligence safer using a new algorithm that learns from human feedback.
Both companies are experts in reinforcement learning – an area of machine learning that rewards agents if they take the right actions to complete a task under a given environment. The goal is specified through an algorithm, and the agent is programmed to chase the reward, like winning points in a game.
Reinforcement learning has been successful in teaching machines how to play games like Doom or Pong or drive autonomous cars via simulation. It’s a powerful method to explore an agent’s behavior, but it can be dangerous if the hard-coded algorithm is wrong or produces undesirable effects.
A paper published in arXiv describes a new method that could help prevent such problems. First, an agent carries out a random action in its environment. The reward predicted is based on human judgement, and this is fed back into the reinforcement learning algorithm to change the agent’s behavior.
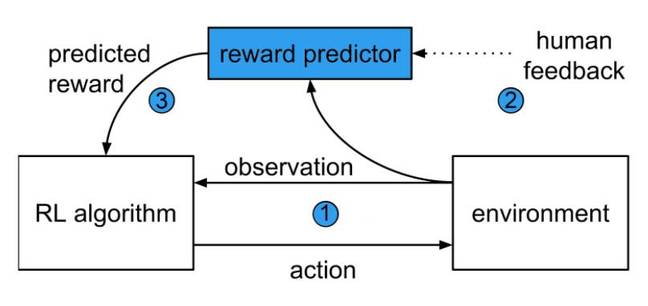
The system learns the goal from working out the best actions to take, after human guidance
The researchers applied this to the task of teaching what looks like a bendy lamp post to backflip. Two short video clips of the agent are shown to a human, who picks which one is better at backflipping.
Over time, the agent gradually learns how to narrow down on the reward function that best explains the human’s judgements to learn its goal. The reinforcement learning algorithm directs its actions and it continues to seek human approval to improve.
It took less than an hour of a human evaluator’s time. But for more complex tasks like cooking a meal or sending emails, it would require more human feedback, something that could be financially expensive.
Dario Amodei, co-author of the paper and a researcher at OpenAI, said reducing supervision was a potential area to focus on for future research.
“Broadly, techniques known as semi-supervised learning could be helpful here. Another possibility is to provide a more information-dense form of feedback such as language, or letting the human point to specific parts of the screen that represent good behavior. More information-dense feedback might allow the human to communicate more to the algorithm in less time,” he told The Register.
The researchers have tested their algorithm on other simulated robotics tasks and Atari games, and results show the machines can sometimes achieve superhuman performance. But it depends heavily on the human evaluator’s judgements.
“Our algorithm’s performance is only as good as the human evaluator’s intuition about what behaviors look correct, so if the human doesn’t have a good grasp of the task, they may not offer as much helpful feedback,” OpenAI wrote in a blog post.
Amodei said that at the moment the results are limited to very simple environments. But it could be useful for tasks where it’s difficult to learn because the reward function is hard to quantify – such as driving, organizing events, writing, or providing tech support. ®
