This article is more than 1 year old
CompSci boffins find Reddit is ideal source for sarcasm database
In pleasing irony, Redditors tag their snark and make themselves ideal test subjects
Over here at El Reg, we think that chatbots are, like, the best thing ever.
Not.
But would they be any better if they could detect sarcasm and retaliate with their own snide remarks?
A group of computer scientists from Princeton University, USA, certainly think so. Mikhail Khodak, Nikunj Saunshi and Kiran Vodrahalli, all graduate students, have pooled together “a large self-annotated corpus for sarcasm” by trawling through Reddit.
“Since sarcasm often involves humans stating something opposed to their beliefs or wants, it is important for chatbots and intelligent assistants to be able to understand when a person is being sarcastic,” Khodak told The Register.
A paper released on arXiv shows the trio aren’t the first group to collect a bit of internet sass. Other researchers have done it with Twitter. Indeed, IBM last week proclaimed a breakthrough of sorts with a new service that can detect when Twitter users are "frustrated, sad, satisfied, excited, polite, impolite and sympathetic."
The authors of this paper decided to turn to Reddit, the self-described “front page of the internet” because posts are written more clearly and aren’t restricted by the 140 character limit on Twitter.
Reddit is essentially an online forum that is split into "subreddits" for different topics or themes. Users follow interesting subreddits, and can rate and comment on posts.
Its structure makes it the perfect place to hunt for a bit of sark. Instead of relying on humans to label individual comments as sarcastic or not, geeky users frequently add ‘/s’ to their posts to denote sarcasm (the markup is a nod to a theoretical ‘<sarcasm>...</sarcasm>’ HTML tag. The subreddit feature also allows researchers to sort their data by subject.
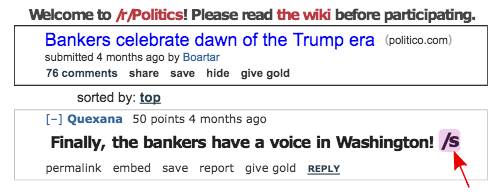
Example sarcastic comment in the politics subreddit, marked with '/s'.
That markup's gold for researchers because it means they've been able to create a data set of 1.3 million self-described pieces of sarcasm among 500-600 million comments made on Reddit from 2009-2016. Controversial and less moderated subreddits like politics or men’s rights, a thread “for those who wish to discuss men’s rights and the ways said rights are infringed”, contain more sneering statements than games or science.
The goal is to construct a dataset sophisticated enough to follow online conversations and understand the context behind the sarky comments in order to test natural language processing algorithms.
“It is quite difficult for both machines and humans to distinguish sarcasm without context. One of the advantages of our corpus is that we provide the text preceding each statement as well as the author of the statement, so algorithms can see whether it is sarcastic in the context of the conversation or in the context of the author’s past statements,” Khodak explained.
But although context is given, trying to make machines understand it is tricky. “We didn't provide context to the machine learning algorithms because there is no standard accepted way of doing this,” Khodak added.
So instead, the researchers focused on training some of the simplest existing algorithms to detect sarcasm on single sentences only. In natural language processing, words are often represented as feature vectors in space, using a “support vector machine”, a classifier that sorts labelled data into two different categories - in this case ‘sarcastic’ and ‘not sarcastic’ - by drawing a divide in the space.
Three different word-embedding algorithms were pitted against humans to judge if a remark was acerbic. Some of the models performed better without added context than humans did to the researchers surprise.
But a closer look shows the results are to be taken with a pinch of salt. Humans are obviously better at understanding sarcasm, no machine is complex enough to really understand text and can’t handle the subtleties of satire.
Instead, the algorithms learned by finding patterns between words that were more closely associated with sarcasm such as “clearly” or “totally”. “Common words do seem to provide a strong indication of sarcastic intent,” Khodak admitted.
Oscar Wilde famously said: “Sarcasm is the lowest form of wit”. Although the database might give researchers a better chance at cracking sarcasm, it’ll be a long, long time before machines are smart enough to understand us. ®
