This article is more than 1 year old
Baidu teaches AI 'baby' bots English by ordering them around a maze
First step in developing family robots with general intelligence
AI researchers at Chinese tech beast Baidu have attempted to teach virtual bots English in a two-dimensional maze-like world.
The study “paves the way for the idea of a family robot,” a smart robo-butler that can understand orders given by its owner, it is claimed. This ability to handle normal language is essential to creating machines with human-level intelligence, the researchers argue in a paper now available on arXiv.
Teaching bots language by describing the simulated world around them gives the software knowhow and knowledge that can be transferred from task to task – that's surprisingly hard to do correctly and a sign of general intelligence. The researchers compare their method to parents using language to coach a baby who is learning to walk and talk.
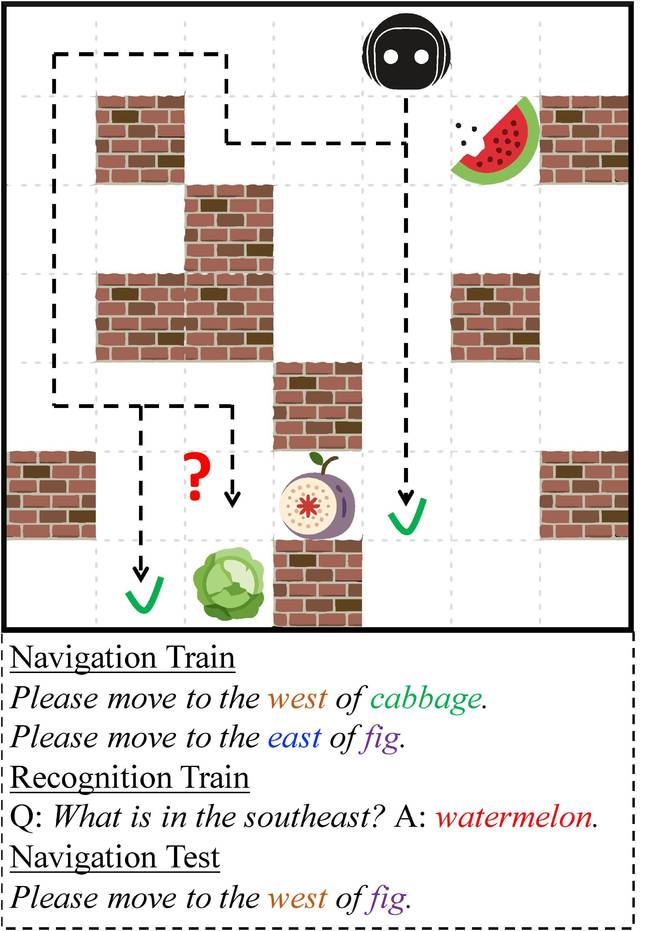
In the simulated 2D world, known as XWORLD, the baby is the agent and the parents are the teacher. The baby agent perceives the environment as a sequence of raw-pixel images and is given a command in English by a teacher.
“By exploring the environment, the agent learns simultaneously the visual representations of the environment, the syntax and semantics of the language, and how to navigate itself in the environment,” the paper said.
Each bot can do four actions: move up, down, left or right. At the start of a session, a teacher issues a natural language command, such as “please navigate to the apple.” A timer is started and the agent must move to the apple within a certain time frame to receive a positive reward. If it fails to do so, a negative reward is given.
It’s not as straight-forward as it seems, as other fruits like a banana, an orange, and a grape are added to confuse the bot. To succeed, it must learn the words for each different type of fruit, which it does through trial and error over thousands of sessions during training.
The virtual agent finds out the correct action it needs to take from the words given in the command.
Example command given in a particular session (Image credit: Yu et al)
It does this by splitting the task into four parts:
- A language module to process the command and generate answers.
- A recognition module that picks out the relevant words in the command.
- A visual perception module that allows the agent to see its local environment.
- An action module to execute a move.
For example, imagine if the agent is to the south of a banana and the east of an apple. If it asked, “where is the banana?” the correct answer would be “north.” It has to understand the command using the language module, know the spatial relation between itself and the banana using its visual perception module, realize the difference between an apple and a banana using the recognition module, and then answer the question using the action module.
Although the bot achieves an average of 90 per cent accuracy in performing the navigation and recognition tasks, XWORLD is a simple environment. The teacher has a tiny vocabulary of 104 words, including nine locations, four colors and 40 distinct object classes. It can speak a total of 16 types of sentences, with four navigation commands and 12 types of recognition classes. The sentence length uttered by the teacher ranges from two to 12 words, and the bot can only reply in single-word answers.
There are other challenges to creating a fully functional robo-servant, Haonan Yu, co-author of the paper and research scientist at Baidu, told The Register.
“Compared to a 2D world, a 3D world needs a more sophisticated visual perception module, because the same object might look quite different from different angles. Reliably detecting an object in all situations is crucial for connecting it to the corresponding linguistic concept.
Also, in 3D, the agent’s view is partial: it cannot always observe the whole world. This requires some memory mechanism of the agent to store past visual information in order for it to navigate.”
But Baidu is hopeful that the vision and language components can be developed to create a family robot one day.
“Imagine that in the future, intelligent robots are shipped from factories to families without being pre-programmed to perform specific tasks. For ordinary people who don’t know how to program, natural language is the most natural way to train a robot for a family.
“Different families might have different special needs from the robot. For example, some people need the robot to make coffee. So they can train the robot by giving it an instruction like 'can you make me a coffee with one spoon of sugar and two spoons of milk?' Because each family trains their own robot in a unique way by natural language, they will have a unique robot in the end,” Yu concluded. ®
