This article is more than 1 year old
Meet the Tesla of the backup world – Datos IO (no, it doesn't make boxes that catch fire)
Data protection for distributed software
Analysis Startup Datos IO is the Tesla of the backup industry, redesigning data protection for distributed apps and focussing on high-end customers with code to solve specific problems no one else can solve anywhere near as well.
It now has ten paying customers for its RecoverX distributed database backup product, six months after its June 2016 launch. We have discussed it here and here. The software uses semantic deduplication as part of its armory, and that's what we are going to look at here.
RecoverX backs up non-relational databases running on-premises or in the Amazon Web Services (AWS), Google and other clouds. V1.5 RecoverX supports Google Compute Engine and Google Cloud Storage. It helps Google Cloud Platform users protect their next-generation apps hosted on non-relational databases (NoSQL, cloud, graph and more) deployed in IaaS and PaaS environments.
The ten represent financial services, retail, eCommerce, media and entertainment, healthcare, and internet of things (IoT). Ayla Networks is the IoT customer and Datos IO backs up its AWS cloud infrastructure and non-relational databases. It bought RecoverX after finding script-based backup unsuitable because of costs and inability to scale.
The retail customer is a Fortune 100 big-box home improvement retail business that migrated its existing e-commerce applications from on-premises data centers to public cloud with the Google Cloud Platform (GCP), to meet compliance standards and enhance operational efficiency.
Cassandra DBA Ishinder Singh's tweet asking if Datos IO had won Home Depot as a customer
Another customer is Barracuda Networks.
Datos IO says "RecoverX is founded upon Consistent Orchestrated Distributed Recovery (CODR), next-generation scale-out data protection architecture that is based on elastic compute services that can be auto-scaled with load, removes the dependency on media servers, and transfers data in parallel to and from file-based and object-based secondary storage. CODR allows RecoverX to provide scalable versioning so that enterprises can protect and back up their data at any interval and granularity. It enables one-click, orchestrated and repair-free recovery for both operational recovery and test/dev use cases, as well as industry-first semantic de-duplication that allows customers to save up to 70 percent on secondary storage costs."
So what is semantic deduplication? A downloadable PDF from Datos IO's webpage is a research paper by several authors, including Datos IO cofounders CEO Tarun Thakur and CTO Prasenjit Sarkar. Its abstract discusses the backup and restore problem of next-generation eventually consistent storage systems (NECST – think non-relational databases like Cassandra and MongoDB) and suggests "a deep semantic understanding of the data stored within the system of interest as a solution."
The paper describes how such "modern systems no longer store data on disks (or SSDs) within a single machine, but rather spread data across many machines in replicated fashion; the replication is implemented in an eventually consistent manner ... The core problem, as we outline, is simple: that tools and systems cannot readily obtain an efficient, consistent, and logical view of data beneath these complex, diverse, and distributed NECST systems."
And then they say:
We believe that the key to success centers upon a deep semantic understanding of the data being stored within these new storage systems. Only by monitoring and inspecting I/O traffic and reconstructing its meaning (i.e., whether a quorum has been reached, or exactly how a particular data item has been replicated) can critical NECST management functions be implemented in an efficient and scalable manner.
Thus the first characteristic of semantic deduplication is that it is app-aware, with the app being the non-relational database.
Attributes of the semantic understanding, or database operation structural understanding, include:
- Quorum reconciliation – Unlike traditional storage, where it is relatively easy to tell when an update has taken place, the simple task of knowing when an update has been committed to the storage system is challenging. NECST systems demand that tools and systems that are interested in what is stored within them understand the basics of how quorums are formed, and exactly how and when a data item is safely replicated within the system. By having a comprehensive understanding of the NECST replication protocol, a backup tool can determine the order of updates and form a coherent view of storage.
- Redundant-copy detection – Unlike traditional striped or mirrored systems, in which redundancy is easily observed, NECST systems may encode data copies in a non-bitwise-identical fashion. Thus, a NECST backup or archival system must be able to meticulously comb through the NECST system to determine where logically identical copies reside, so as to be able to coalesce them and thus achieve storage-efficient backup.
- Configuration-oblivious backup and restore – Distributed systems have frequent configuration changes, scaling up to meet new demands or down when a failure occurs and a system is removed from operation. NECST tools must be able to store, and then recreate, data despite the fact that its configuration has changed.
Datos IO's CODR software "takes a full snapshot of the database of interest; after this, CODR tracks changes applied to the database and generates incremental versions for the changes." A version is "a cluster consistent snapshot of a scale-out distributed database." We're told:
Full and incremental snapshots are transferred, in parallel, to a backup storage system, which can be a single node in smaller deployments, or a cluster in larger-scale settings. At the backup store, CODR must process the collection of local snapshots to realize a version. CODR achieves this end by running an integrated quorum and semantic-deduplication algorithm, resulting in a single, space-efficient copy of the data.
This means that CODR must have algorithms inside it that are specific to individual database products and cannot simply be pointed at a new database product about which it has no semantic (operation structural) knowledge.
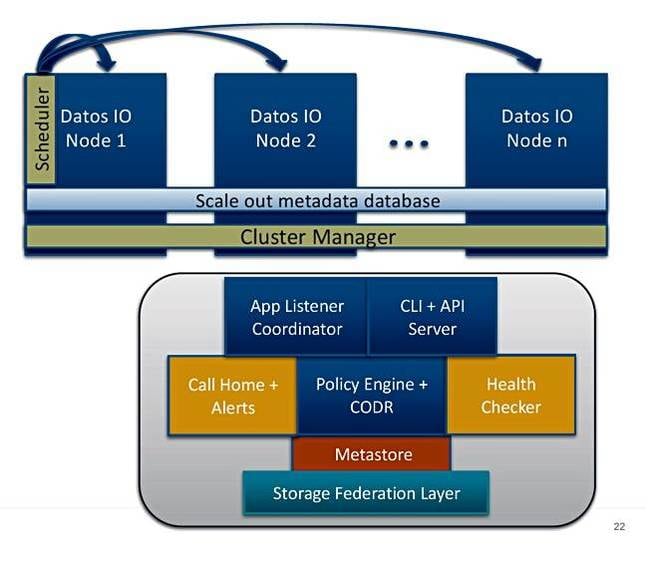
CODR deployment schematic
You can explore what Datos IO says about how CODR works here and there are several videos.
RecoverX has an annual subscription license with the notion of a capacity tier based on physical database size ($/TB). Having gained just ten customers in six months suggests that the pricing is not cheap, and that customers may need to suffer a degree of pain from their current backup and recovery operations before switching to Datos IO.
Why did we start this article by saying Datos IO is the Tesla of the backup industry? Assume Veeam, Veritas and Dell EMC are the Ford, GM and Chrysler of backup software. We think that Datos IO, like Tesla, is redefining how you do backup by going its own clever way, and focussing on a well-designed and high-end product to build its business. (No, stop thinking about cars catching fire or crashing.)
We're sure it will expand its database coverage in the future and potentially collide with the Veeams and Veritas' in the market, which will make for interesting times in the backup industry. ®
