This article is more than 1 year old
Splunk slam dunk as FC SAN sunk by NVMe hulk
ESG says Apeiron NVMe array delivers real time Splunk goods
Case study Apeiron has had its Splunk processing speed advantage confirmed by ESG. Big deal. So what?
The deal is that Splunk was built as a distributed and scale-out Big Data ingest and search engine running across multiple servers each with their own storage, providing real-time access to data analytics. Because data sets grew, ESG says Splunk began to be implemented with its software running on distributed servers while the data was put on a shared array. This generated a problem down the line as the dual controller array head became an IO bottleneck, and real time became wait-for-a-long-time.
What is needed, Apeiron says, is the speed of direct-attached storage for servers and the capacity of a SAN. Step forward its ADS1000 array, which uses NVMe drives and RDMA over Ethernet (NVMe over Ethernet it says) to give each accessing server local flash storage speed less than 1.5 μS of network latency, which is trivial.
It had ESG run a test validation at technology integrator WWT, a $9bn revenue corporation, using a dataset of syslog data holding 70 billion events.
Splunk
As we understand it, Splunk ingests data and analyses ingested data*. To enable that, it has an input parsing pipeline and indexing pipeline and a separate search facility operating on the generated indices. Typically, in its scale-out design, indexing software would run on separate servers, accept data from a forwarding facility, then parse it (if unparsed), index it and store the raw data and the indices on storage – either local to the server or on a central SAN.
Searches come in through search heads, which are directed to the indexers, which then use the indices and raw data to generate the results. Search and ingest can be concurrent and the overall process is IO-intensive. The chart diagrams this process with the storage being a 24 x NVMe flash drive Apeiron ADS1000 array accessed over 40Gbit/s Ethernet.
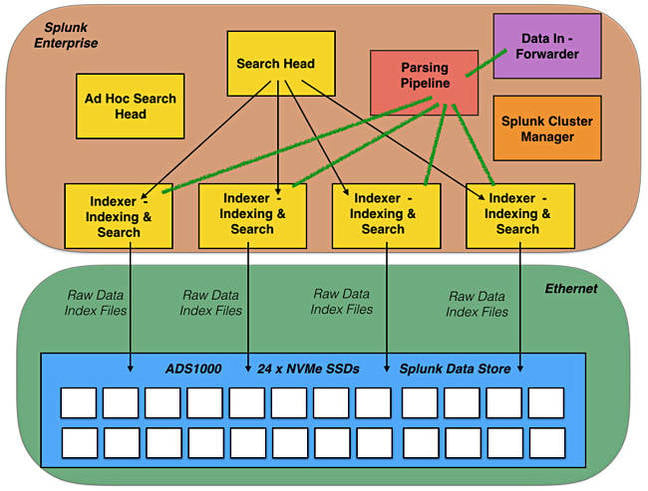
ESG’s Apeiron and Splunk test.
ESG testing
ESG ran a series of tests over several weeks using seven ingesting and analysing servers and a 2U ADS1000. Four servers were configured as indexers, one server as the Enterprise Security (ES) search head, another as an ad hoc search head, and seventh as the Splunk cluster manager. Splunk version 6.5 was used for testing and standard Splunk performance and monitoring tools reported the results. All 60 out-of-the-box ES correlation searches were run in parallel with ad hoc queries, dense queries, and data ingestion.
The ADS1000 ingested at 10TB - 12TB a day while running concurrent queries, and 20TB/day with no querying. ESG says “a similarly configured Splunk reference architecture with one search head and four indexers using a traditional storage back-end would yield results in the 1TB/day range.”
On search, the Apeiron set-up was radically faster than an existing Splunk reference architecture system, with ESG running three different search types: rare, super sparse, and sparse.
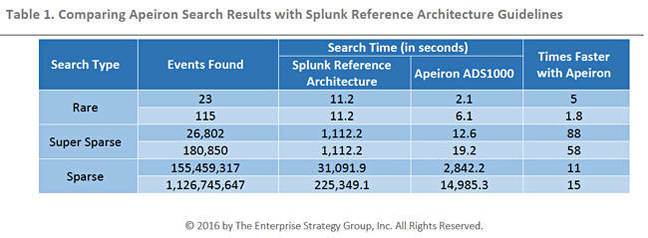
ESG results on Splunk search. The 225,3491.1 secs number is 2.6 days while the 14,985.3 secs number us 4.16 hours.
ESG says “Apeiron outperformed the reference architecture across all tests. The super sparse results show that Apeiron completed two different searches 58x and 88x faster. The sparse results highlighted an order of magnitude improvement that could be gained with Apeiron: One dense search with the reference architecture took more than 2.5 days, while Apeiron completed the task in just over 3.5 hours.”
Take-away
If your SAN or filer is causing IO bottlenecking for Big Data application runs, then rescue is at hand. Conversely, if your distributed server plus local storage setup for such application runs is reaching capacity and management and complexity limits then rescue could be at hand again. In both cases, you can switch to an NVMe-accessed flash SAN (of any flavour, of course).
Read the ESG case study (PDF) for a closer look at its test results.
The specific take-away is that Apeiron’s ADS1000 blows away traditional SANs and filers as Splunk data stores. The general message is that NVME-accessed flash arrays combine the speed advantages of local server flash with the central management and capacity advantages of a SAN to enable high-capacity, high-speed Splunk processing, a Splunk slam-dunk. ®
* Splunk's documentation is here.
