This article is more than 1 year old
Meet the 1,000 core chip that can be powered by an AA battery
Big claims from UC Davis’ Kilocore caper
Six years after University of Glasgow researchers first achieved the feat, an American university has demonstrated a 1,000 core processor.
While Glasgow used a FPGA, the “kilocore”silicon produced by the University of California Davis’ VLSI* Computation Lab differs by putting 1,000 independently programmable cores on a single custom die.
According to the team, that’s a record – there’s a list here.
The latest Kilocore processes a theoretical maximum of 1.78 trillion instructions per second and contains 621 million transistors. It was demonstrated in Honolulu at the 2016 Symposia on VLSI Technology and Circuits.
IBM fabricated the chip based on 32nm technology. According to the researchers, the chip can execute 115 billion operators a second while dissipating only 0.7W, requiring only a AA battery.
According to the paper, titled A 5.8 pJ/Op 115 Billion Ops/sec, to 1.78 Trillion Ops/sec 32nm 1000-Processor Array by Brent Bohnenstiehl, Aaron Stillmaker, Jon Pimentel, Timothy Andreas, Bin Liu, Anh Tran, Emmanuel Adeagbo, Bevan Baas, at 0.84V the array has 12 memory cores. The 1000 cores execute 1 trillion instructions/sec while dissipating 13.1 W.
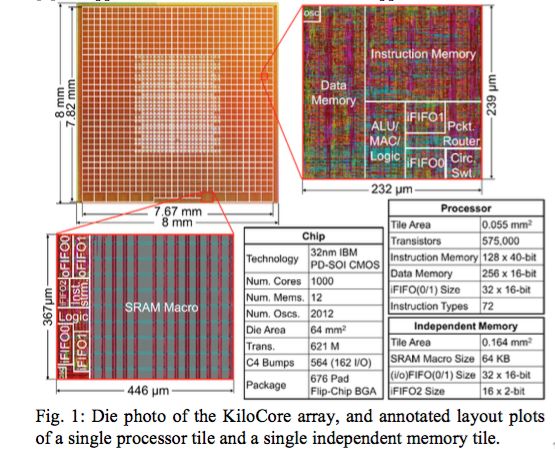
"Each processor issues one in-order instruction per cycle into its 7-stage pipeline from either its 128 x 40-bit local instruction memory or an independent memory module," the Honolulu paper explains.
"Communication on-chip is accomplished by a high-throughput circuit-switched network and a complementary very-small-area packet-switched network. The source-synchronous circuit-switched network supports communication between adjacent and distant processors, as resources allow, with each link supporting a maximum rate of 28.5 Gbps," according the paper. This dissipates 16 per cent less energy than fetching instructions from local memory.
Europe's best effort to date – excluding FPGAs – has been the Kalray chip, which embedded 256 user cores and 32 system cores on a 28nm die. (pdf)
Intel’s best shot at VLSI is its Xeon Phi co-processor line described in depth here.

Amdah's Law
Pic credit: Daniels220 some rights reserved
Increasing the number of transistors on a chip doesn’t correspond a linear increase in performance; Amdahl’s Law comes into play. Some workloads – those which are easily parallelisable and which have few shared dependencies – benefit more from a multicore chip than other tasks. The classic example is 3D video rendering, dubbed “embarrassingly parallelisable”. Other bottlenecks include access to shared resources.
Much of the intellectual hefty lifting to solve these problems remains outstanding. ®
* Very Large Scale Integration, obvs.
