This article is more than 1 year old
Hortonworks adds Ambari control freak to Hadoopery
Downloads and business are booming for open source data munching
Hortonworks, the Yahoo! spinoff that has emerged as the third supplier of commercial support for the Apache Hadoop big-data muncher, is ramping up its Data Platform to the 1.2 release, which includes better security, enhancements to HCatalog data sharing and HBase database services that ride on top of Hadoop, and integration of the Ambari graphical management tool that was in tech preview when Hortonworks kicked out its 1.0 release last June.
John Kreisa, vice president of marketing at Hortonworks, tells El Reg that the integration of the Ambari Hadoop installation and management tool is the most important new feature being added with Hortonworks Data Platform 1.2. At the moment, Ambari only runs on Red Hat Enterprise Linux 5 and 6 and its CentOS clones, but the Apache sub-project that hangs off Hadoop is working on support for SUSE Linux Enterprise Server 11, and hopes to have it available soon.
In the initial commercial Hadoop releases from Cloudera and MapR Technologies, the system-management tools were closed source and fee-based, or were given away as part of a support contract sold to cover the open source parts of the Apache Hadoop stack. The fact that Ambari is just bundled with the HDP stack and is, like the rest of that stack, completely open source is seen by Hortonworks as being a key differentiator.
With the Ambari tool, Hadoop administrators can set up, configure, and troubleshoot the big data–munching clusters, including graphical representations of MapReduce jobs running on the system and performance metrics to show how jobs are doing and what resources are loading up what nodes in the cluster.
The Ambari tool also has a database that keeps track of the historical performance of jobs and the nodes in the cluster so you can see how these change over time, and also has an "instant insight" health-check button for all of the core elements of the Hadoop stack. There is also a cluster-navigation feature that allows you to jump into the NameNode settings for any particular node in the cluster.
The NameNode, by the way, is the key part of a Hadoop cluster that keeps track of where data is replicated in the system and which knows where to dispatch computing jobs to those data chunks for it to be chewed on. The JobTracker keeps track of what MapReduce jobs are running around the cluster, chewing on data like locusts swarming a crop.
Ambari, which is coded in Java like the core Hadoop MapReduce and Distributed File System code, and which runs on a Tomcat or other Java application server, also has a REST interface that allows you to programmatically go into the Hadoop cluster and initiate commands, as well as integrating with Microsoft System Center, Teradata Viewpoint, or other system-management tools common in the data center.
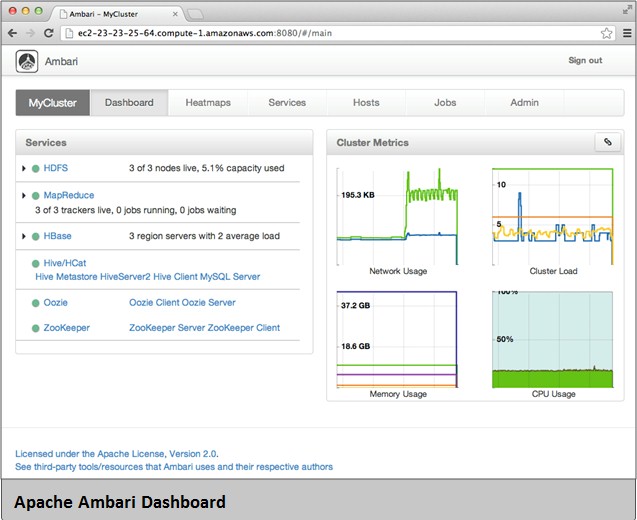
Screenshot of the Ambari Hadoop management client in HDP 1.2
The Ambari tool will work with the original HDP 1.0 release as well as the HDP 1.1 release that came out in September 2012, and it will also help do cluster upgrades as customers upgrade their HDP releases. With Ambari in place, you can upgrade the Hadoop stack all at once or in piecemeal fashion, module by module. But Kreisa says that the intent is to use Ambari with the HDP 1.2 release and get everything current.
"We are never more than six commits away from the open source trunk, where our competition is a thousand commits away," brags Kreisa.
He was exaggerating the latter number for effect, but stressed that because HDP was a 100 per cent open source distribution of Hadoop, and one that is created by the core Yahoo! team, being current was one of the advantages that it could bring to bear. While Hortonworks got a later start, Kreisa says that the rate of change with the pure open source projects is going to be much higher and will soon blow by the open-core variants of Hadoop from Cloudera and MapR.
The HDP 1.2 release also has an enhanced security model for the Hive data warehousing and ad hoc querying layer for HDFS and the HCatalog metadata service. The latter is a table and storage management service that allows MapReduce, Pig, Hive, and Streaming – a kind of super-scripter for MapReduce jobs – to share data across those modules even though it is stored in different formats.
The security in the HDP 1.2 stack has a "pluggable authentication model" that restricts access to Hive while at the same time allowing multiple concurrent queries to be processed by Hive concurrently. This code also has stability improvements and performance tweaks, and there is a new ODBC driver that comes from Simba Technologies that can suck data out of and pump date it into Hive. (This ODBC driver is available on Cloudera and MapR distributions, by the way.)
The other thing that Hortonworks is eager to talk about aside from HDP 1.2 is how business is going. Back in June 2012, when HDP 1.0 came out, the company had around 75 employees, and in six months it has added 100 more in engineering, sales, marketing, and support roles to help feed its growing business.
While not naming names or giving out specific numbers, Kreisa says that it has had tens of thousands of downloads of the HDP stack and has a couple dozen "very big-name" paying customers running its HDP stack on production clusters.
Teradata and Microsoft have both linked tails and noses with Hortonworks for their Hadoopery. Teradata partnered with Hortonworks as HDP 1.0 was coming out to integrate Hadoop with its Aster Data database, and a couple of these deals have closed already. Microsoft will soon ship its HDInsight Hadoop service, which is in beta testing right now on its Azure cloud.
Hortonworks does not provide a full list price for its Hadoop distro, and interestingly it is charging for its support contracts based on the size of a cluster instead of on a per-node basis like its rivals. A standard support contract (biz hours, five days a week) runs $12,000 per year for a ten-server cluster. ®
