This article is more than 1 year old
HP rolls out Hadoop AppSystem stack
Lashes elephants to Autonomy, Vertica
Everybody wants to get a piece of the Hadoop elephant in the room, and luckily for Hewlett-Packard the mad scramble to make sense of big data is just at the beginning of its hype cycle and there's time enough to get some choice cuts.
 As part of its Discover customer and partner extravaganza in Las Vegas this week, HP has rolled out a new AppSystem for Apache Hadoop integrated stack, The company is also talking up the ability to link the Hadoop Distributed File System and Hadoop applications with the company's two other major (and relatively recently acquired) big data software tools.
As part of its Discover customer and partner extravaganza in Las Vegas this week, HP has rolled out a new AppSystem for Apache Hadoop integrated stack, The company is also talking up the ability to link the Hadoop Distributed File System and Hadoop applications with the company's two other major (and relatively recently acquired) big data software tools.
These are the Vertica column-oriented distributed database and the Autonomy Intelligent Data Operating Layer (IDOL) 10 stack, which creates contextual information from unstructured text, audio, and video data to make it "understandable."
HP is not about to shell out a lot of money to try to buy a Hadoop distie, although a strong case could be made that perhaps it should have already done such a thing, even if the current top Hadoopers – Cloudera, Hortonworks, and MapR – would probably be too expensive relative to the revenues and profits they currently generate.
Just like HP never did buy a Linux distributor or a database maker, the company will play Switzerland and work on preconfiguring Hadoop stacks on its servers, storage, and switches and peddle add-on consulting services to IT shops and integration with its Vertica data store and Autonomy data organizer to make its dough off big data.
The AppSystem for Apache Hadoop is a reference architecture of components, just like similar AppSystems for running the Vertica data store and data analytics and data warehouse appliance software from Microsoft and SAP and email messaging setups running Windows and Exchange.
Just like HP is not picking just one data store or database for the various AppSystems launched in the last year, HP is not about to play favorites with the Hadoop distros, either. But, because HP is not silly, it is starting out with the fully open source distro from Cloudera, known as Cloudera Distribution for Hadoop, or CDH3 for short in the current release.
Specifically, the AppSystem for Hadoop loads the 64-bit edition of Red Hat Enterprise Linux 6.2 on ProLiant server nodes and then layers on the CDH3 Update 3 Hadoop toolset, which includes the core Hadoop MapReduce workload scheduler and the Hadoop Distributed File System (HDFS) as well as a slew of related open source tools to pumping data into and querying data stored in that file system.
HP's reference architecture as embodied in the AppSystem set up also encourages customers to get the Cloudera Manager 3.7.5 add-on for the CDH3u3 distribution. Steve Watt, chief technologies for Hadoop and big data at HP, tells El Reg that Cloudera Manager does a lot of Hadoop-specific, node-level configuration tasks that can make life a whole lot easier for Hadoop cluster admins. (You don't want to have to change a setting manually in 2,000 nodes, now do you?)
Some of the software in the AppSystem for Hadoop comes from HP, which is good. HP is adding in its own Insight Cluster Management Utility v7.0 software, which is a traditional HPC cluster tool that does deployment, management, and monitoring of software stacks running on nodes in a cluster. HP is also weaving in its own Insight Control v7.0 for Linux server management tools, which let admins drilled down and manage at the node level.
The AppSystem for Hadoop reference architecture is not just a recipe for software, of course, but also a very precise configuration for running a production-grade Hadoop instance. And this is what makes any reference architecture interesting because the presumption is that the IT vendor has done the capacity planning homework so you don't have to. This particular setup is designed to fit into a single rack.
There's one management node for running the HP software stack and the Cloudera Manager, one Hadoop namenode (which spreads the data over the nodes in the cluster running HDFS), one JobTracker node (which issues MapReduce jobs to the nodes for data munching), and 18 worker nodes (which is where the data replication and munching happens). Here's how it is configured:
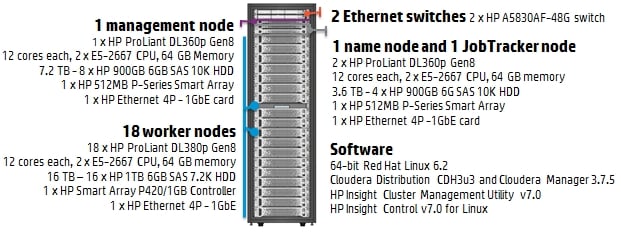
HP's AppSystem for Hadoop reference architecture (click to enlarge)
The interesting bit is that HP is putting six-core Xeon E5-2667 processors running at 2.9GHz and slightly more than one disk spindle per core into the worker nodes. (With the modern Hadoop setups, you like to have at least one spindle per core, according to various people we have spoken to as they build their reference architectures.)
The other thing to note is that Gigabit Ethernet is perfectly fine, and the nodes don't have huge wonking chunks of memory, either. As you need to add capacity to this AppSystem for Hadoop, you slide in racks of 2U ProLiant DL380 Gen8 nodes, and you can put 19 of these in a rack with some room left over for a switch and a slideaway.
One of the problems with Hadoop clusters, says Watt, is that you can't get a visual sense of what is going on inside of the cluster as jobs are running, and people being inherently visual (well, most of us anyway), this is a drawback. So HP is bolting on its Cluster Management Utility onto the Hadoop cluster and letting admins see what the cluster is doing in terms of bottlenecks. Here's what the tool's interface shows:
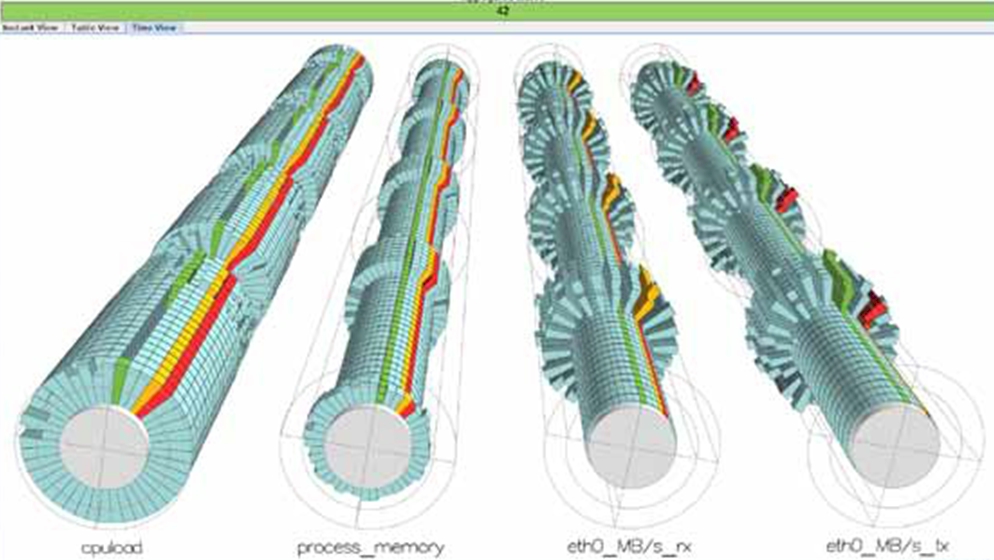
Cluster Management Utility for AppSystem for Hadoop (click to enlarge)
Each one of those cylinders is composed of a timeslice that shows the aggregate CPU load, memory consumption, and Ethernet bandwidth both transmitting and receiving on each node of the Hadoop cluster.
As workloads expand and contract, so do the cylinders, and you can fly along the cylinders and drill down into them to do troubleshooting as you try to deal with bottlenecks. Hadoop tops out at around 4,000 nodes in a single instance (using CDH3 or any other distribution, since it is a limit of the namenode), which is well below the largest clusters that HP has in the HPC space using this tool.
At the moment, explains Paul Miller, vice president of solutions and strategic alliances for the Enterprise Servers, Storage and Networking group, HP does not have an OEM agreement with Cloudera and will be encouraging customers to buy their own licenses to Cloudera Enterprise, which includes tech support for CDH3 as well as the Cloudera Manager tool (which is not open source). And HP plans on putting together other Hadoop stacks, too.
"The Hadoop market is in its infancy right now, and different workloads will work differently on various distributions," says Miller. "Se we are going to be open and support HortonWorks, MapR, and Cloudera."
The reference architectures for all three Hadoop distributions will be available later this month, and HP expects for its Factory Express system configuration service to be able to build a complete AppSystem stack on the Cloudera stack by the fourth quarter of this year. (Why is this taking so long you ask? Good question, and while HP did not answer it, the suspicion at the Reg Elephant Desk is that it is tied to a future release of Cloudera software.)
Big Data strategy boutique
HP Technology Services is also trying to get in on the Hadoop action, with a Big Data Strategy Workshop to help IT shops try to figure out what big data they have and the best ways to chew through it. The services arm of ESSN is also running the Roadmap Service for Apache Hadoop services engagement, which is really a best practices and capacity planning session for newbies.
In both cases, you can bet Meg Whitman's last dollar that there will be lots of talk about Vertica and Autonomy during those sessions. These are fee-based engagements, although HP did not say how much they cost; presumably if you are paying, the sales pitch is more subtle and experts actually impart some knowledge.
On the Autonomy front, HP has announced the capability to put the IDOL 10 engine, which supports over 1,000 file types and connects to over 400 different kinds of data repositories, onto each node in a Hadoop cluster. So you can MapReduce the data and let Autonomy make use of it. For instance, you can use it to feed the Optimost Clickstream Analytics module for the Autonomy software, which also uses the Vertica data store for some parts of the data stream.
HP is also rolling out its Vertica 6 data store, and the big new feature is the ability to run the open source R statistical analysis programming language in parallel on the nodes where Vertica is storing data in columnar format. More details on the new Vertica release were not available at press time, but Miller says that the idea is to provider connectors between Vertica, Hadoop, and Autonomy so all of the different platforms can share information. ®
